DB, SQL
DB - 정규화
- -
정규화
- DB의 테이블이 잘 만들어졌는지 평가하고, 잘 만들지 못한 테이블을 고쳐나가는 과정
- 테이블을 정규형(NF, normal form)이라고 불리는 형태에 부합하게 만들어감
- 일반적으로 3NF에 부합하는 데이터베이스를 보고 "정규화된 데이터베이스"라고 부름

- 제 n정규형 등으로 부르며, 순서에 따라 규칙이 누적됨

- 대부분의 경우 제 3정규형에 부합하기만 하면 잘 정규화된 DB라고 표현
- 정규화를 하면 DB에서 삽입/업데이트/삭제 이상을 제거할 수 있다
- 새로운 종류의 데이터를 추가할 때 테이블 구조 수정을 많이 하지 않아도 된다
- DB구조의 단순화 > 사용자가 더 쉽게 이해 가능
- 데이터 모델을 만들고 실제 DB에 구현하기 전에 적용하면 좋음 (DB 수정이 번거롭기 때문)

1. 제 1정규형 (1NF)



+
- 1NF를 확대해서 해석 한다면, 컬럼을 늘리는 방법은 1NF를 지킨다고 볼 수 없음
- 이유: 1NF를 지키기 위해서 단순히 테이블의 컬럼을 늘리게 된다면 구조적으로 NULL이 많이 생기게 되는 문제가 발생
>> NULL은 아무 값도 없는, 즉 0개의 값을 저장, 0개는 단일 값, 즉 하나의 값에 해당하지 않음
- 한 컬럼에 같은 종류의 값을 여러 개 저장하고 있을 때 > 해당 컬럼을 하나의 테이블로 분리해서 모델링
- 한 컬럼에 서로 다른 종류의 값을 여러 개 저장하고 있을 때 > 한 컬럼을 여러 개로 분리해서 모델링
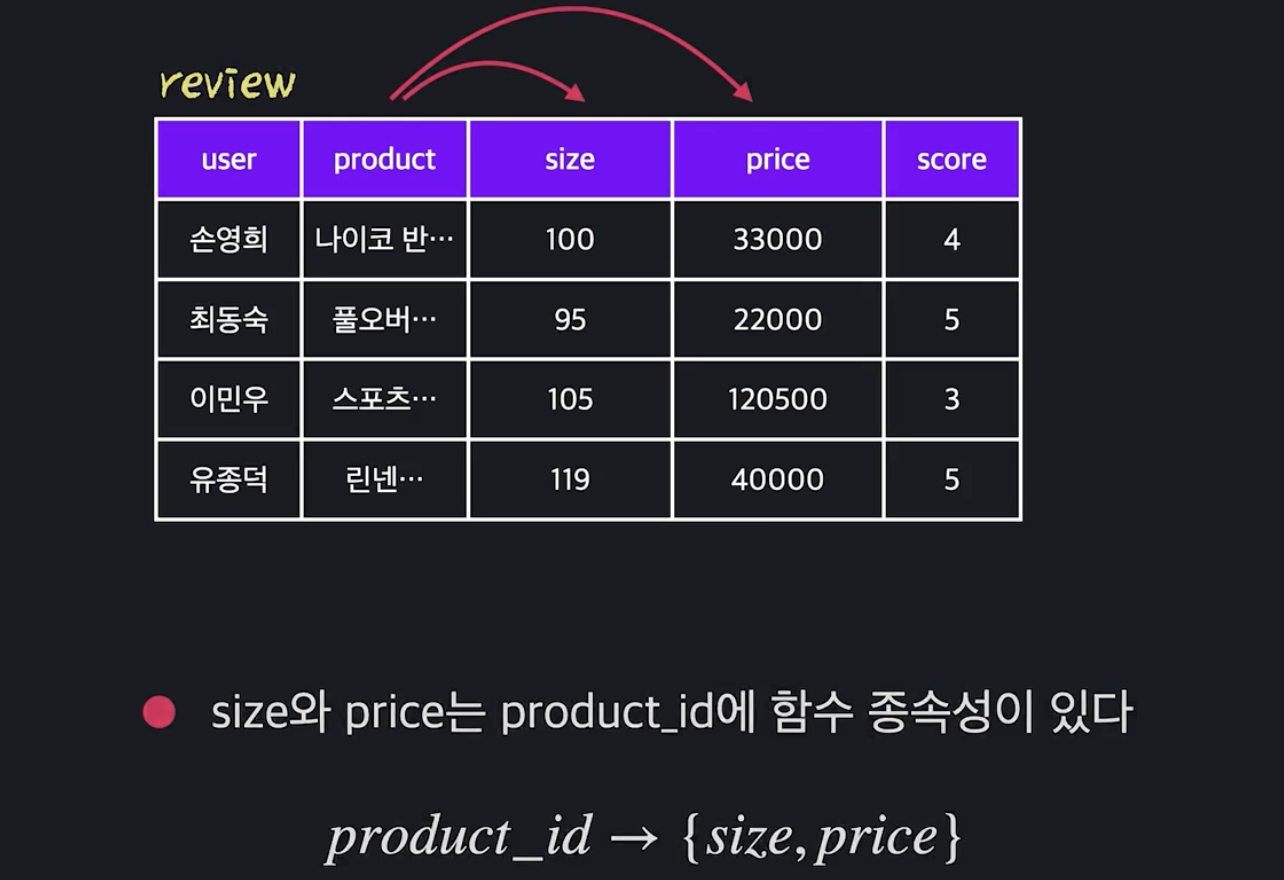
2. 함수 종속성(Functioinal Defendecy)
- 테이블 안의 어트리뷰트 사이에서 생기는 관계




- user의 이메일은 중복될 수 없음 > 하나의 유저를 특정지을 때 사용 가능 > 유저의 이메일을 통해 나머지 값이 결정된다 할 수 있음
>>
name, age, gender는 email에 함수 종속성이 있다. (그 반대는 아님)
- 함수 종속성에는 이행성이라는 속성이 있다

- 하나 이상의 어트리뷰트를 건너서 함수 종속성이 있는 경우에 함수 종속성이 넘어갔다(이행됐다)라고 표현
>>
brand_country는 product_id에 이행적 함수 종속성이 있다
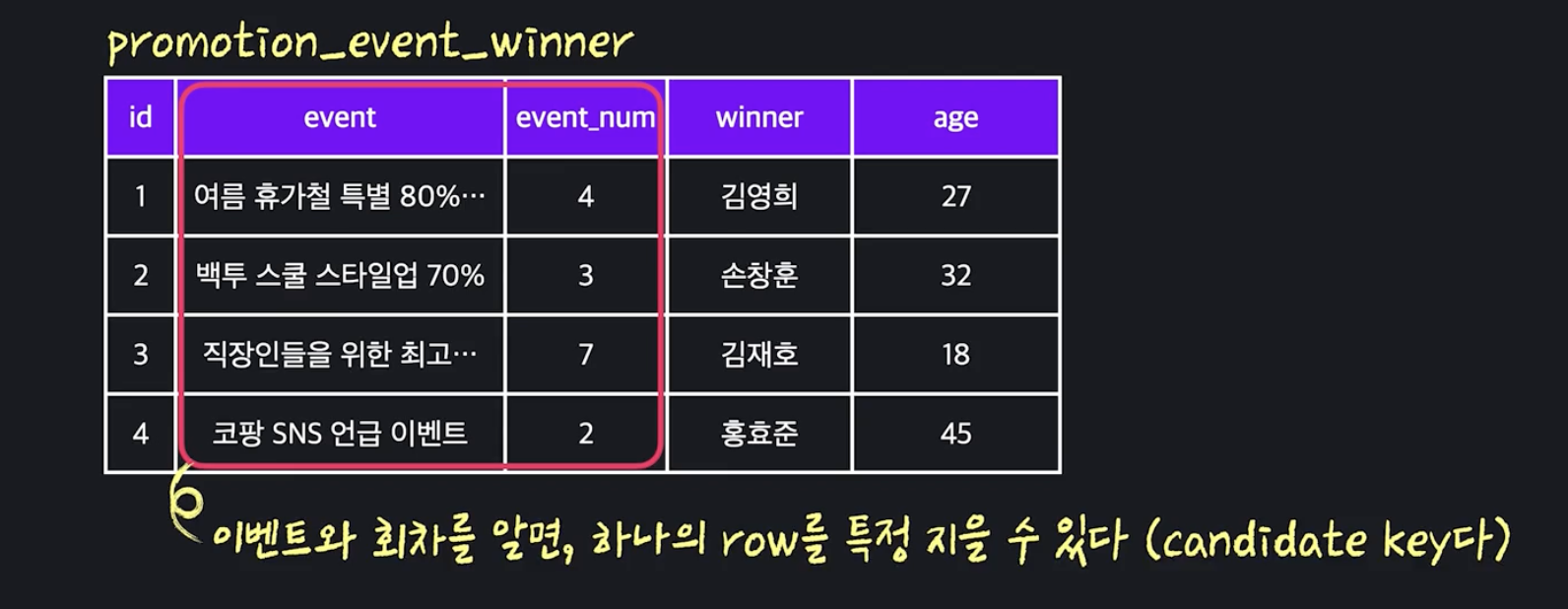
3. candidate key
- 하나의 로우를 특정지을 수 있는 어트리뷰트들의 최소 집합


- 여러개의 candidate key가 존재할 수 있지만, primary key는 하나만 존재 가능

- candidate key에 포함된 어트리뷰트는 프라임 어트리뷰트라고 부름
(위 경우 id / user_id / product_id 가 프라임 어트리뷰트)
4. 2NF / 3NF
2NF


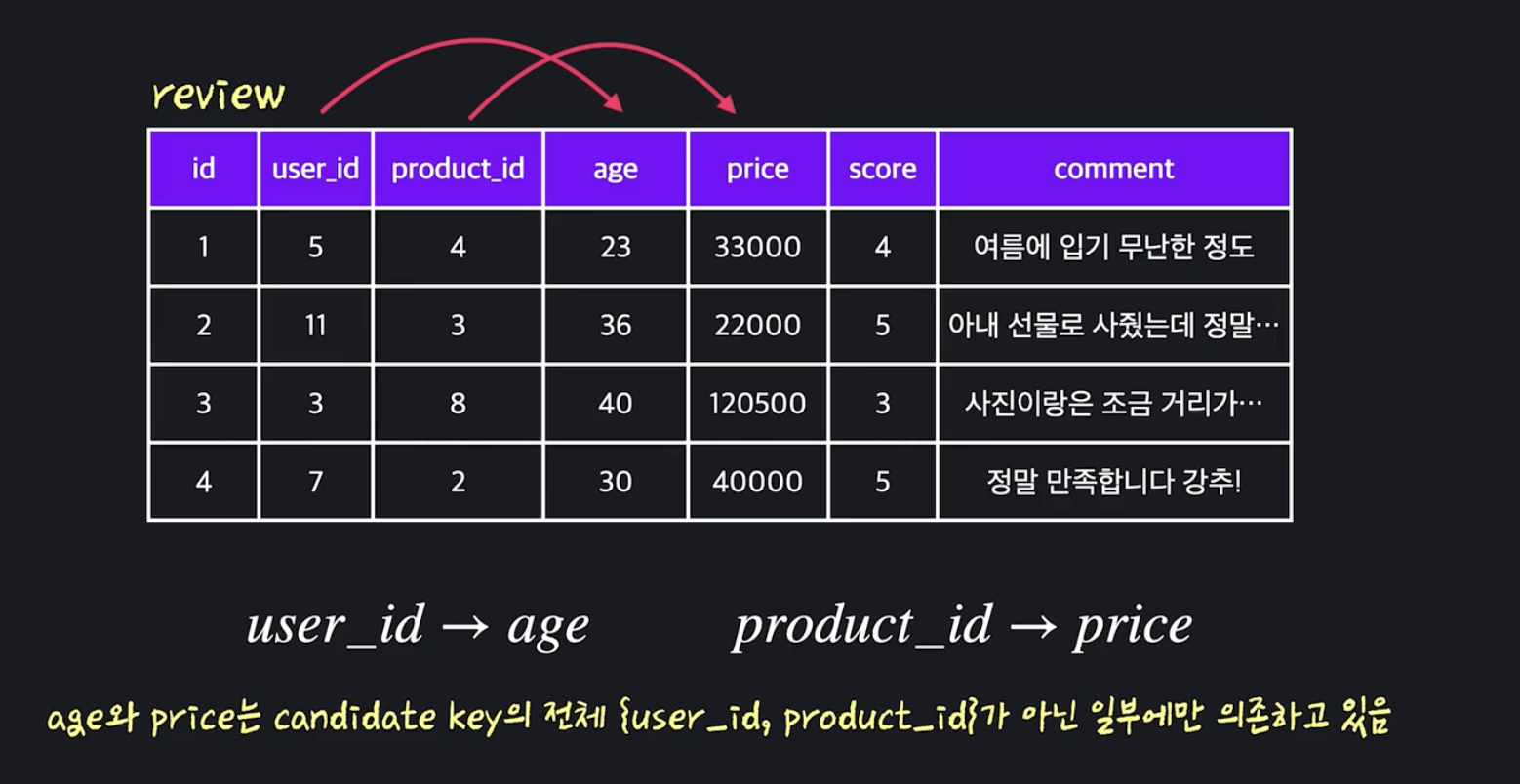

- 옮겨줄 테이블이 없으면 새로운 테이블을 만들어 거기에 저장
3NF


- 2NF에 부합하는 테이블

- 3NF에 부합하기 위해선 이러한 이행적 함수 종속성도 존재하면 안됨
>>
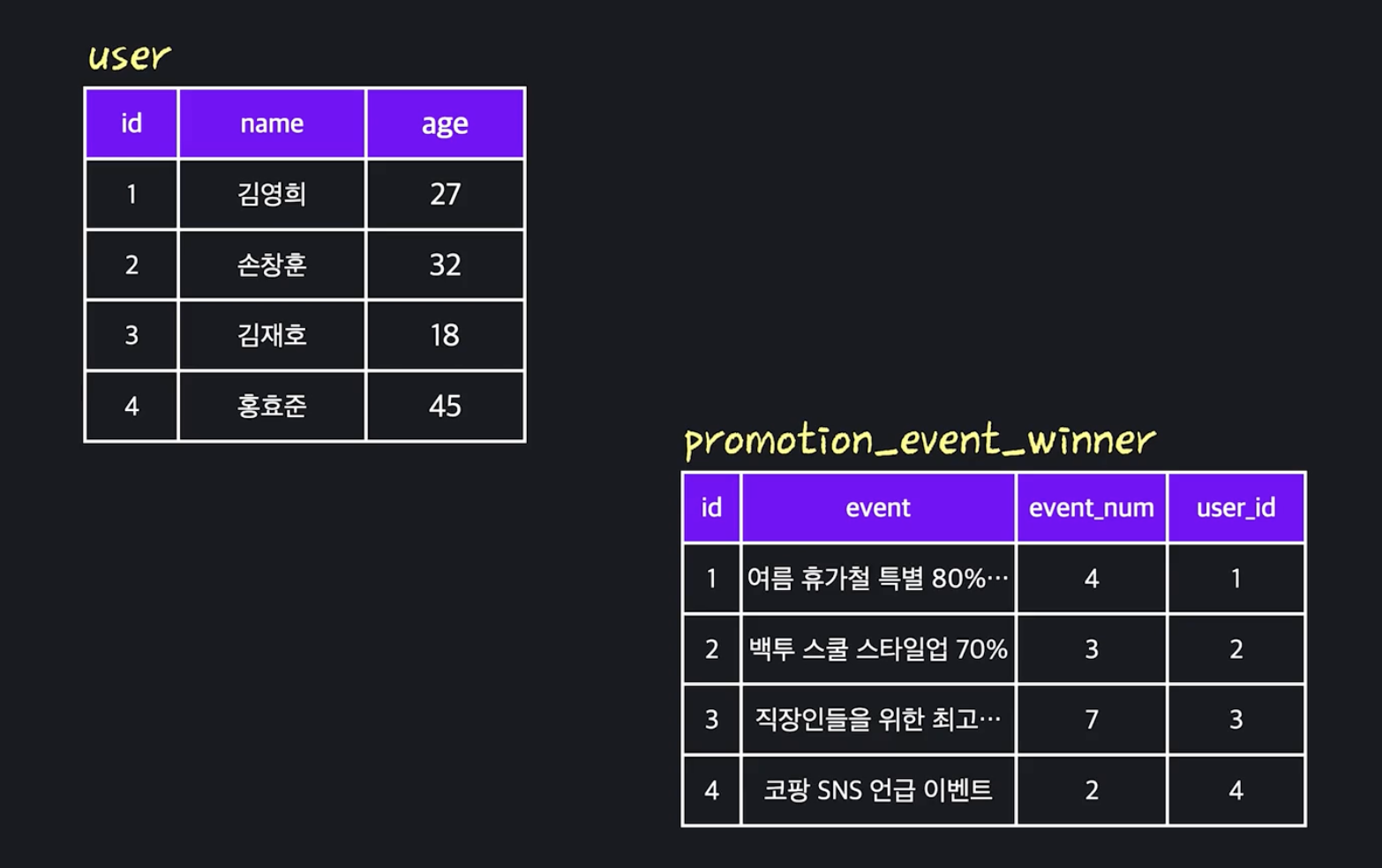
새로운 테이블 생성 후 이행적 함수 종속성이 있는 어트리뷰트를 생성한 테이블에 옮기고 그 테이블에 대한 외래키 칼럼을 추가
예제)

1NF


2NF

- 현재 테이블은 1NF에 부합하고 있기 때문에 2NF에 부합하기 위해서는 candidate key의 일부분에만 의존하는 non-prime attribute은 없어야 함
A. 테이블의 candidate key와 non-prime attribute들을 파악
( id는 attribute 하나만으로 모든 상품을 특정지을 수 있기 때문에 생각하지 않고 여러 attribute의 조합으로 만들어지는 candidate key에 대해서만 생각 )
B. 상품 이름 name, 브랜드 이름 brand, 그리고 크기 size, 이 세 attribute이 있으면 하나의 상품을 특정 지을 수 있음
> {name, brand, size} 이게 하나의 candidate key
C. 각 non-prime attribute의 함수 종속성 파악

- 상품은 딱 하나의 브랜드만 가질 수 있음
- 브랜드는 수많은 상품을 가질 수 있음
- brand와 product 사이에는 1:N 관계 > product 테이블에 foreign key를 넣어줘서 관계를 모델링
- 상품은 여러 개의 크기와 재고를 가질 수 있음
- 특정 크기와 재고는 항상 하나의 상품에만 대한 내용
- product와 product_size_stock은 1:N 관계 > product_size_stock 테이블에 foreign key를 넣어줘서 관계를 모델링

3NF
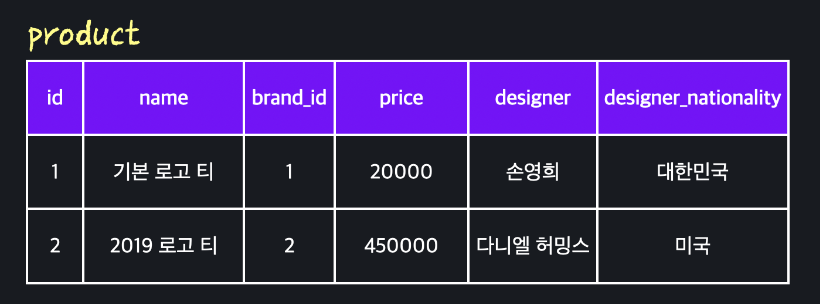
A. 이행적 함수 종속성 파악
(id > designer > designer_nationality)
B. 테이블 분리

- 하나의 상품은 하나의 디자이너에 해당하고, 디자이너는 여러 상품 가능 > 상품과 디자이너는 N:1 관계
- product 테이블에 foreign key를 넣어줘서 관계를 모델링

>> 정규화 과정을 통해 1개의 테이블이 6개로 분리됨
( 중복되는 데이터 등 모델링 실수로 생기는 데이터베이스 이상 현상을 웬만해서는 다 예방할 수 있음 )

'DB, SQL' 카테고리의 다른 글
| DB - 타입 정리 (0) | 2023.03.31 |
|---|---|
| DB - 인덱스 (0) | 2023.03.31 |
Contents
소중한 공감 감사합니다